With the rise of Large Language Models (LLMs) like OpenAI's GPT-4 and Anthropic's Claude, the demand for efficient ways to handle and process the vast amounts of data they utilize has surged. Many might be familiar with the standard relational databases, but the unique requirements of LLMs often require the use of more specialized tools.
Because of this, we've seen a new type of database emerge: Vector databases.
A vector database is a specific kind of database designed to convert data – usually textual data – into multi-dimensional vectors (also known as vector embeddings) and store them accordingly. These vectors act as mathematical depictions of characteristics or qualities. The number of dimensions in each vector can vary widely, spanning from just a few to several thousands, based on the data's intricacy and detail level.
This allows for efficient and effective analysis and comparison of data points, enabling tasks such as similarity searches and clustering. The use of vectors in a database can greatly enhance data processing capabilities and enable advanced data-driven applications.
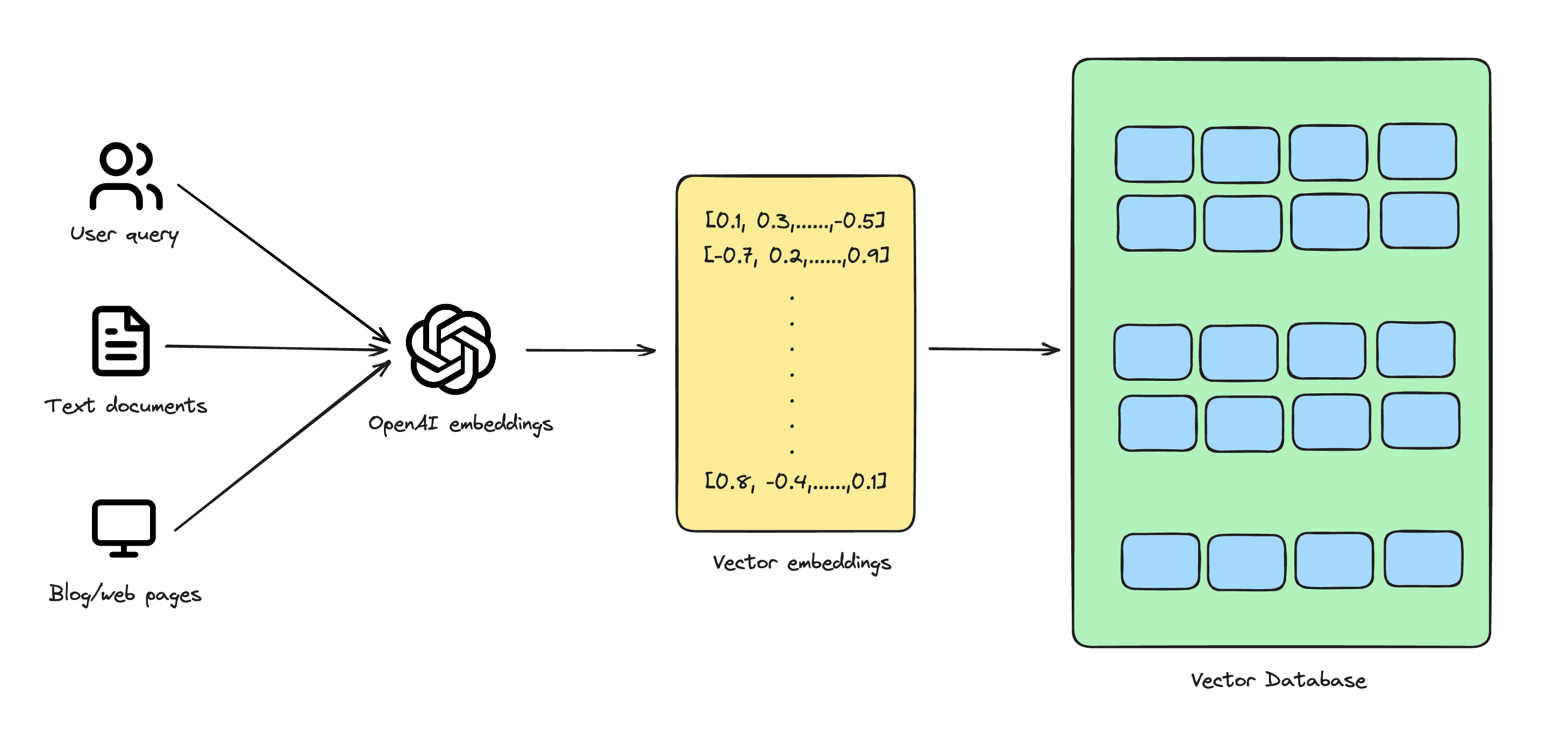
Imagine you're writing a lengthy research paper, and instead of reading each page individually, you have a special folder that turns every page into a unique bar code. These bar codes represent the main points and details of each page. Some bar codes might be simple with just a few lines, while others are incredibly complex with thousands of lines, depending on the depth of the content on that page.
Now, if you want to find pages with similar themes or group them by topics, you just have to compare their bar codes quickly. This method makes managing and understanding your research much easier and more efficient, just like how vector databases handle and analyze data.
There are several vector databases available in the market today. Here are some of the most popular ones, based on the usage we've seen in AI apps built on Vercel.

Using a vector database is not very different from using any other kind of database, though the operations you'd perform might vary based on the specific nature of vector data. Here's a simple guide to get started:
- Installation & Setup: Begin by choosing the right vector database for your needs. Once chosen, follow the provided installation guide. Many databases offer cloud-based solutions, so setup can be as simple as creating an account.
- Data Ingestion: Import your vector data into the database. This step might require you to convert your data into a vector format if it isn't already.
- Querying: Once your data is in place, you can start querying the database to find similar vectors or perform analytical operations. Most vector databases will provide you with a query language or an API that's tailored to handle vector operations.
- Maintenance & Scaling: As with any database, you'd need to monitor performance, handle backups, and ensure that your database scales with your needs.

