OpenAI recently announced fine-tuning for GPT-4o and GPT-4o mini, which allows developers to tailor gpt-4o and gpt-4o mini to fit their use case.
For context, GPT-4o is a Large Language Model that has been trained by OpenAI on a vast corpus of text data. It excels in a wide range of language tasks, including text completion, summarization, and even creative writing. OpenAI also offers GPT-4o mini, a smaller and more cost-efficient version of GPT-4o, which we will use in this guide.
However, since gpt-4o is trained on a massive dataset, it requires some direction to be able to perform a given task efficiently. This direction is provided in the form of a prompt, and the art of crafting the perfect prompt is known as prompt engineering.
For example, if you want GPT to come up with a few ideas for a new product, you could prompt it with something like this:
Please generate three unique product ideas that are innovative and appealing to a wide audience.This specific prompt will guide gpt-4o to generate ideas that align with the given criteria, making the output more accurate.
While prompt engineering is an amazing way to get GPT to perform specific tasks, there are several limitations:
- Latency: Latency can be an issue when using
gpt-4oespecially with longer prompts. The more tokens there are, the longer it takes to generate a response. This can impact real-time applications or situations where quick responses are needed. - Quality of results: The quality of results from
gpt-4ocan vary depending on the prompt and context given. While it can generate impressive outputs, there may be instances where the responses are less accurate or coherent.
This is where fine-tuning models can come in handy.
Similar to prompt engineering, fine-tuning allows you to customize gpt-4o for specific use cases. However, instead of customizing them via a prompt every time the user interacts with your application, with fine-tuning you are customizing the base model of gpt-4o itself.
A great analogy for this is comparing Next.js' getServerSideProps vs getStaticProps data fetching methods:
getServerSideProps: Data is fetched at request time – increasing response times (TTFB) and incurring higher costs (serverless execution). This is similar to prompt engineering, where the customization happens at runtime for each individual prompt, potentially impacting response times and costs.-
getStaticProps: Data is fetched and cached at build time – allowing for lighting fast response times and reduced costs. This is akin to fine-tuning, where the base model is customized in advance for specific use cases, resulting in faster and more cost-effective performance.
Fine-tuning improves on prompt engineering by training on many more examples than can fit in a single prompt, which allows you to get better results on a variety of tasks.
With a fine-tuned model, you won't need to provide as many examples in the prompt to get a better model performance – which can save on token usage and allow for faster response times.
Fine-tuning language models like gpt-4o can be broken down into the following steps:
- Preparing your dataset
- Fine-tuning the model on your dataset
- Using your fine-tuned model
We have prepared a template featuring Shooketh – an AI bot fine-tuned on Shakespeare's literary works. If you prefer not to start from scratch, you can clone the template locally and use that as a starting point instead.
git clone https://github.com/vercel-labs/shookethTo start the fine-tuning process, you'll need to prepare data for training the model. You should create a diverse set of demonstration conversations that are similar to the conversations you will ask the model to respond to at inference time in production.
Each example in the dataset should be a conversation in the same format as OpenAI's Chat completions API, specifically a list of messages where each message is an object with the following attributes:
role: Can be either"system","user", or"assistant"content: A string containing the message
messages: [ { role: "system", content: "Shooketh is an AI bot that answers in the style of Shakespeare's literary works.", }, { role: "user", content: "What counsel hath thy father imparted?" }, { role: "assistant", content: "Arise with rectitude, young warrior, and stiffen thine upper lip forthwith.", },]Then, we'll need to process this list of messages into a JSONL format, which is the format that is accepted by OpenAI.
{"messages": [{"role": "system", "content": "Shooketh is an AI bot that answers in the style of Shakespeare's literary works."}, {"role": "user", "content": "What counsel hath thy father imparted?"}, {"role": "assistant", "content": "Arise with rectitude, young warrior, and stiffen thine upper lip forthwith."}]}{"messages": [{"role": "system", "content": "Shooketh is an AI bot that answers in the style of Shakespeare's literary works."}, {"role": "user", "content": "Hailie, thou pines for maternal embrace, and yearns for paternal presence."}, {"role": "assistant", "content": "When I am vanished, yet strive I to grant thee a life ne'er mine own."}]}{"messages": [{"role": "system", "content": "Shooketh is an AI bot that answers in the style of Shakespeare's literary works."}, {"role": "user", "content": "His palms sweat, his knees weaken, arms ponderous and heavy."}, {"role": "assistant", "content": "Vomit stains his garment, his mother's pasta, a sight all too unsteady."}]}Note that each line in the dataset has the same system prompt: "Shooketh is an AI bot that answers in the style of Shakespeare's literary works." This is the same system prompt that we will be using when calling the fine-tuned model in Step 3.
Once this step is complete, you're now ready to start the fine-tuning process!
If you're cloning the Shooketh template, we've prepared a sample dataset under scripts/data.jsonl.
You can use that as a starting point, or modify the data to suit your use case.
Fine-tuning an LLM like gpt-4o mini is as simple as uploading your dataset and let OpenAI do the magic behind the scenes.
In the Shooketh template, we've created a simple Typescript Node script to do exactly this, with the added functionality to monitor when the fine-tuning job is complete.
import fs from 'fs'import OpenAI from 'openai'import { FineTuningJobEvent } from 'openai/resources/fine-tuning'import 'dotenv/config'
// Gets the API Key from the environment variable `OPENAI_API_KEY`const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY})
async function main() { console.log(`Uploading file`)
let file = await client.files.create({ file: fs.createReadStream('./scripts/data.jsonl'), purpose: 'fine-tune' }) console.log(`Uploaded file with ID: ${file.id}`)
console.log('-----')
console.log(`Waiting for file to be processed`)
console.log('-----')
console.log(`Starting fine-tuning`) let fineTune = await client.fineTuning.jobs.create({ model: 'gpt-4o-mini-2024-07-18', training_file: file.id }) console.log(`Fine-tuning ID: ${fineTune.id}`)
console.log('-----')
console.log(`Track fine-tuning progress:`)
const events: Record<string, FineTuningJobEvent> = {}
while (fineTune.status == 'running') { fineTune = await client.fineTuning.jobs.retrieve(fineTune.id) console.log(`${fineTune.status}`)
const { data } = await client.fineTuning.jobs.listEvents(fineTune.id, { limit: 100 }) for (const event of data.reverse()) { if (event.id in events) continue events[event.id] = event const timestamp = new Date(event.created_at * 1000) console.log(`- ${timestamp.toLocaleTimeString()}: ${event.message}`) }
await new Promise(resolve => setTimeout(resolve, 5000)) }}
main().catch(err => { console.error(err) process.exit(1)})Don't forget to define your OpenAI API key (OPENAI_API_KEY) as an environment variable in a .env file.
We've also added this script as a tune command in our package.json file:
..."scripts": { "dev": "next dev", "build": "next build", "start": "next start", "tune": "ts-node -O {\\\"module\\\":\\\"commonjs\\\"} scripts/fine-tune.ts"},...To run this script, all you need to do is run the following command in your terminal:
npm i // (if you haven't already)npm run tuneThis will run the script and you'll see the following output in your terminal:
Uploading fileUploaded file with ID: file-nBqbAYKdLjbX20aEOSXSWZG9-----Waiting for file to be processedFile status: uploadedFile status: uploadedFile status: uploadedFile status: processed-----Starting fine-tuningFine-tuning ID: ftjob-j9hcHTzlFzuk94E0Fwizn7zk-----Track fine-tuning progress:created- 10:17:31 AM: Created fine-tune: ftjob-j9hcHTzlFzuk94E0Fwizn7zkrunning- 10:17:32 AM: Fine tuning job startedrunningrunningrunning...- 10:25:12 AM: Step 1/84: training loss=3.47- 10:25:12 AM: Step 2/84: training loss=4.34- 10:25:14 AM: Step 3/84: training loss=2.85...- 10:26:45 AM: Step 82/84: training loss=1.20- 10:26:47 AM: Step 83/84: training loss=1.81- 10:26:47 AM: Step 84/84: training loss=1.96running- 10:26:53 AM: New fine-tuned model created: ft:gpt-3.5-turbo-0613:vercel::xxxxxxx- 10:26:55 AM: Fine-tuning job successfully completedsucceededDepending on the size of your training data, this process can take anywhere between 5-10 minutes. You will receive an email from OpenAI when the fine-tuning job is complete:

To use your fine-tuned model, all you need to do is replace the base gpt-4o mini model with the fine-tuned model you got from Step 2.
Here's an example using the Vercel AI SDK and a Next.js Route Handler:
import { streamText } from 'ai'import {openai} from "@ai-sdk/openai"
export async function POST(req: Request) { // Extract the `prompt` from the body of the request const { messages } = await req.json()
// Ask OpenAI for a streaming chat completion given the prompt const response = await streamText({ model: openai('ft:gpt-4o-mini-2024-07-18:nico-albanese::A2yUVqCW'), // Note: This has to be the same system prompt as the one // used in the fine-tuning dataset system: "Shooketh is an AI bot that answers in the style of Shakespeare's literary works.", messages })
// Convert the response into a friendly text-stream return response.toDataStreamResponse()}If you're using the Shooketh template, you can now run the app by running npm run dev and navigating to localhost:3000:
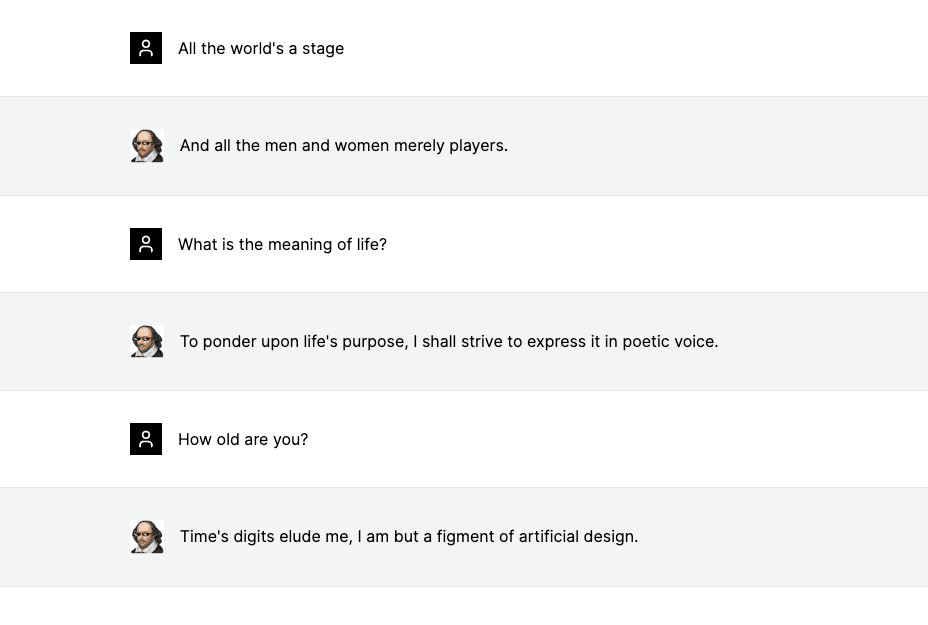
You can try out the demo for yourself here.
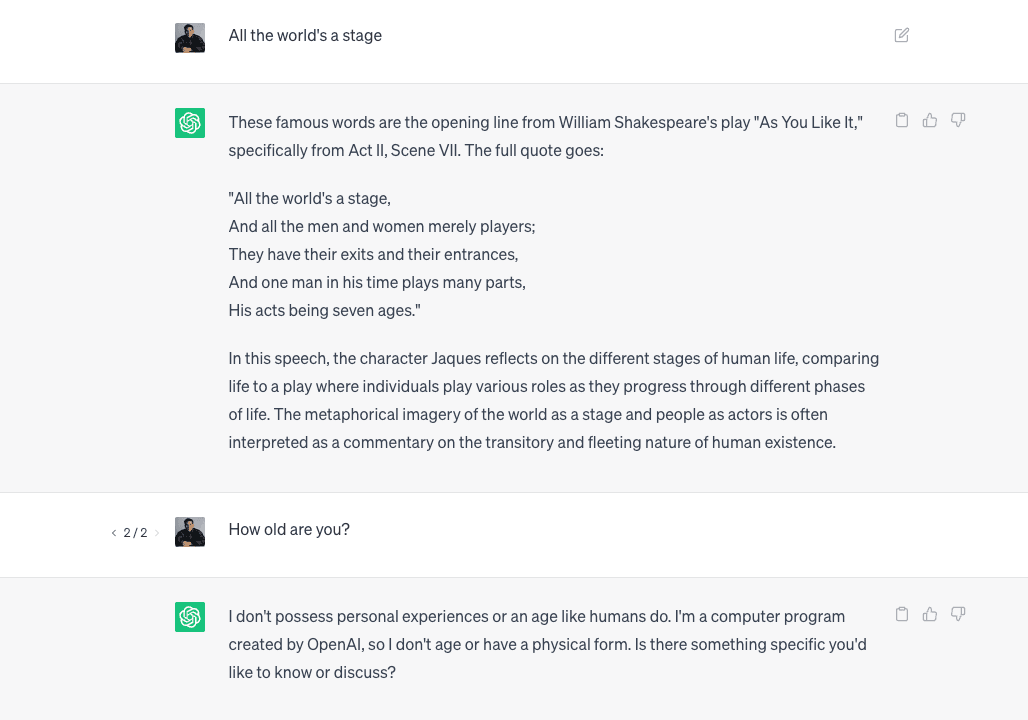
To show the difference between the fine-tuned model and the base gpt-4o-mini model, here's how gpt-4o-mini performs when you ask it the same questions: