This guide shows best practices for connecting to relational databases with Vercel Functions. It includes improvements to address connection leak issues common in traditional serverless environments.
To get started with connecting to your relational database, we recommend using connection pooling with Fluid compute.
- Initialize a connection pool: Within the global scope of your function (or module), create a pool using your chosen database driver (e.g.,
pgfor PostgreSQL ormysql2for MySQL). - Attach a pool: Use the
attachDatabasePoolhelper to handle idle connections. - Handle requests: Each incoming request can fetch a client from that already-initialized pool. This reuses the connection rather than opening a new one.
- Return the connection to the pool: After you’ve executed queries, release the connection back to the pool. In a concurrent environment, other requests can then grab that same connection.
- Define your pool globally: Create your pool in a global scope so multiple requests within the same instance can reuse it.
- Set a low idle timeout: Use a relatively short idle timeout (e.g., 5 seconds) to ensure unused connections are quickly closed while still enabling reuse during high traffic.
- Avoid max pool size of 1: This does not reduce total connections and harms concurrency in Fluid Compute. Instead, keep the minimum pool size to 1.
- Leverage rolling releases: Use Rolling releases to gradually shift traffic between deployments to avoid a surge of new services coming online and connecting to a database.
- Database options: We recommend exploring Postgres database options in the Vercel Marketplace.
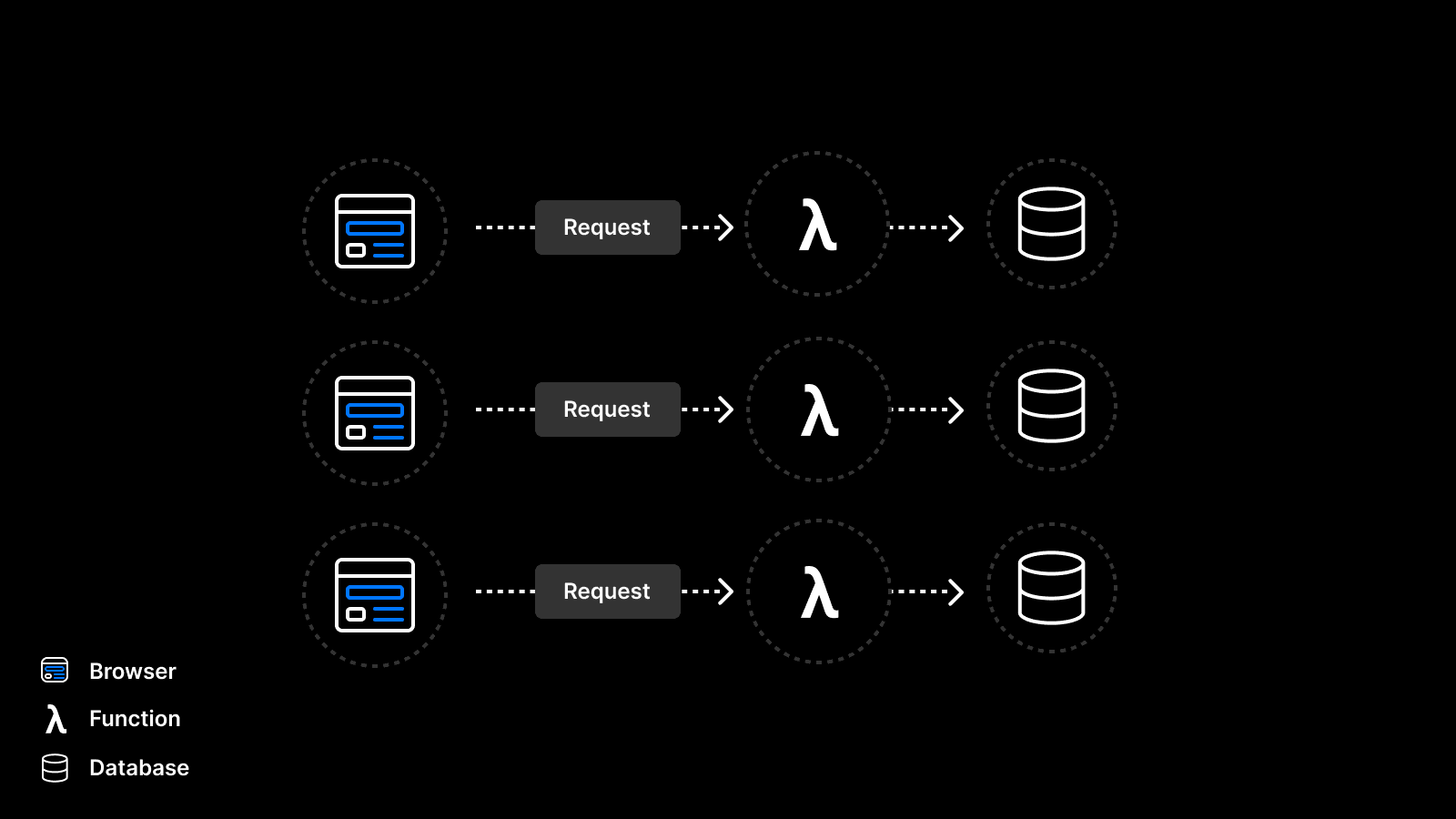
Consider a traditional Node.js server connecting to a SQL database. When a request is made to your application, the server opens a connection to the database to execute a SQL query. After completion, the data is returned and the connection is closed.
At a large scale, creating a connection to your database on every request can exhaust server memory usage and hit the maximum number of connections allowed. One solution is to pay for more memory, and another is to use connection pooling.


Pooling is one solution to prevent your application from exhausting all available database connections. Rather than opening a connection with every request, connection pooling allows us to designate a single "pooler" that keeps an active connection to the database. When a request is made that would read from the database, the pooler finds an available connection rather than creating a new connection.


Traditional relational databases were built for long-running compute instances, not the ephemeral nature of functions.
Functions are stateless and asynchronous. They are not designed for persistent connections to a database. It's easier to exhaust available database connections because functions scale immediately and infinitely when traffic spikes occur.
When a function is invoked, a connection to the database is opened. Upon completion, the connection is closed. Similar to a Node.js server, we want to maximize connection reuse. However, this requires different solutions in serverless environments than connection pooling.

Open source solutions like serverless-mysql and serverless-pg attempt to bring connection pooling to serverless environments. By storing variables outside the scope of the function, these solutions can create a connection pool in between invocations. However, there is no guarantee of connection reuse. Therefore, we recommend other solutions.
Services like Supabase (which uses PostgREST), Hasura, or AWS Aurora Data API expose a managed API layer on top of the underlying database. This allows you to execute SQL statements from any application over HTTP without using any drivers or plugins.
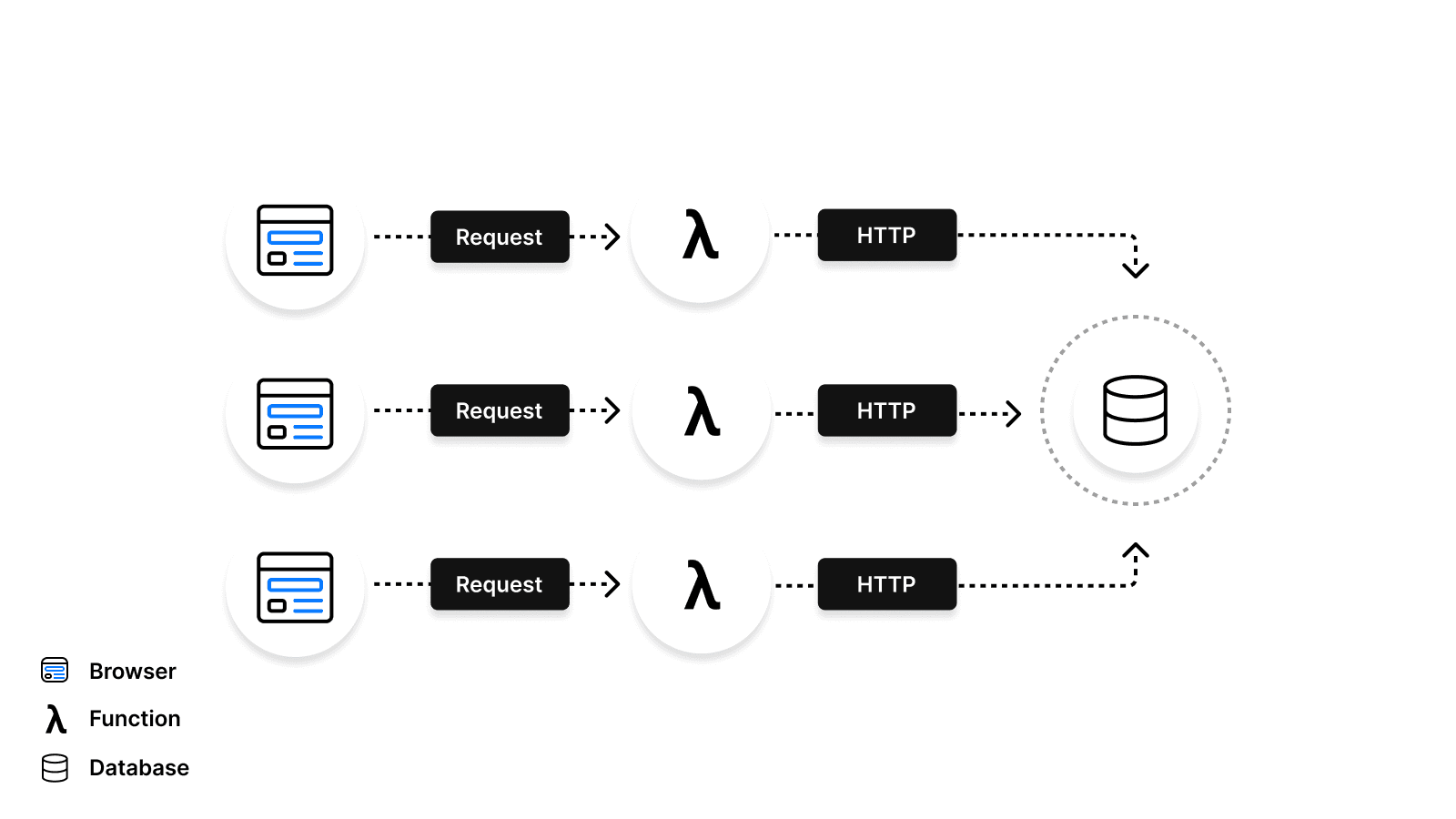

These Data APIs don’t require a persistent connection to the database. Instead, they provide an HTTP endpoint where you can run your SQL statements without managing connections.
When functions are used with connection pools, you can face the following problem when a function is suspended:
- In many serverless platforms, when a function becomes idle, it’s suspended in memory.
- Idle connection timeouts don’t run while suspended, so connections remain open until either the VM shuts down or the database forcibly closes them.
- This can cause “phantom” usage of your connection pool, especially after large deployments or traffic spikes.
By default, functions run in short-lived, isolated environments. This makes it difficult to maintain persistent database connections—especially under heavy load. Fluid Compute changes this by enabling multiple invocations to share a single function instance (and its global state). As a result, you can maintain and reuse database connections without having to open and close them on every request.
Reduced connection overhead: Traditional serverless environments scale by creating new function instances for each burst of traffic. Each instance may open its own connection to the database, often leading to connection limits being hit. With Fluid Compute, when multiple concurrent requests are routed to the same instance, they can reuse the same database connection or connection pool, dramatically cutting down on connection overhead.
Optimized concurrency: Fluid Compute's optimized concurrency allows several requests to run simultaneously within the same instance. This setup closely resembles a traditional server environment that maintains a global connection pool. The difference is that the platform still automatically scales up additional instances as needed—giving you the best of both worlds.
Persistent Global State: Because Fluid Compute does not fully tear down instances between invocations, objects or pools you initialize at a global level remain available for subsequent requests. This allows for strategies such as lazy initialization of your database pool: the first request establishes the pool, and subsequent requests reuse it until the platform decides to spin down that instance due to inactivity or scaling needs.
Solution for the connection leak problem: It provides a lifecycle hook attachDatabasePool that ensures idle connections are closed before suspension. When you attach a pool to your function using this helper, Fluid Compute uses waitUntil to keep the instance alive just long enough to close idle connections after a request completes. This makes connection lifecycle behavior identical to a serverful environment and prevents leaks.