5 min read
We recently launched our AI models v0-1.5-md, v0-1.5-lg, and v0-1.0-md in v0. Today, we're sharing a deep dive into the composite model architecture behind those models. They combine specialized knowledge from retrieval-augmented generation (RAG), reasoning from state-of-the-art large language models (LLMs), and error fixing from a custom streaming post-processing model.
While this may sound complex, it enables v0 to achieve significantly higher quality when generating code. Further, as base models improve, we can quickly upgrade to the latest frontier model while keeping the rest of the architecture stable.
Link to headingWhy does v0 need a composite model architecture?
Most AI models¹ are one of two things: a proprietary model from a frontier model provider or an open-source model from a third-party host.
While building AI products like v0 and tools like the AI SDK, we’ve found limitations with both of these approaches:
Model knowledge can quickly become outdated for topics that change fast
Frontier model labs don’t have the resources or desire to focus on specific use cases like building web apps
v0 specializes in building fast, beautiful full-stack web applications. To do so, we leverage the libraries and frameworks that make up the web ecosystem. Projects like React and Next.js are constantly evolving, and proprietary frontier models almost immediately fall behind on framework updates.
Fine-tuning open-source models offers more flexibility, but as of today, proprietary models outperform open models on tasks relevant to v0 by a wide margin, especially code generation with multimodal input.
Frontier models also have little reason to focus on goals unique to building web applications like fixing errors automatically or editing code quickly. You end up needing to prompt them through every change, even for small corrections.
Our composite model architecture lets us decouple these pieces from the base model. We can pair a state-of-the-art base model with specialized data retrieval, an optimized Quick Edit pipeline, and a custom AutoFix model to improve output.
This allows us to adopt new state-of-the-art base models as they are released without needing to rewrite every step of the process. When you use a v0 model through our API, you get access to this entire pipeline.
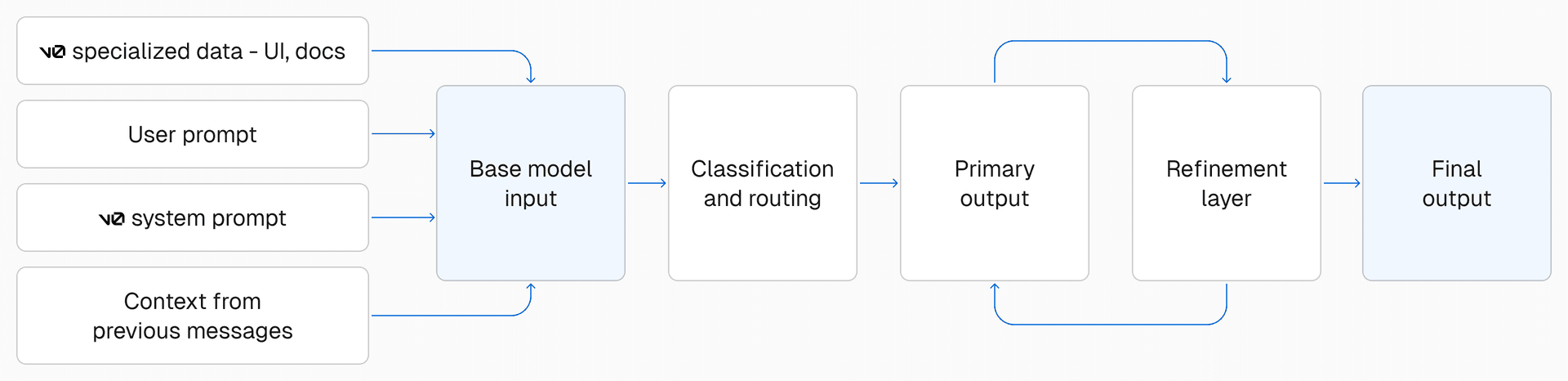
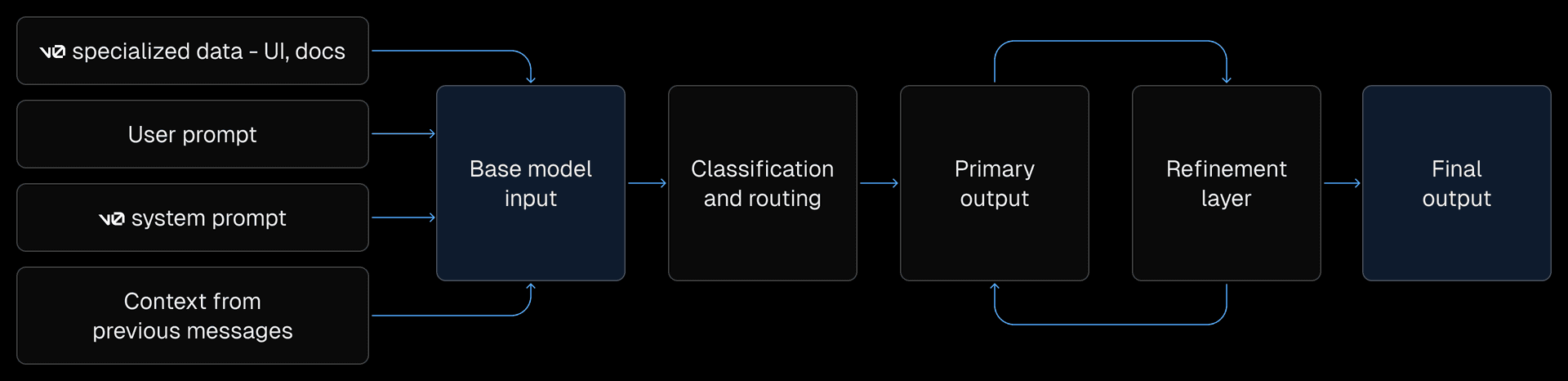
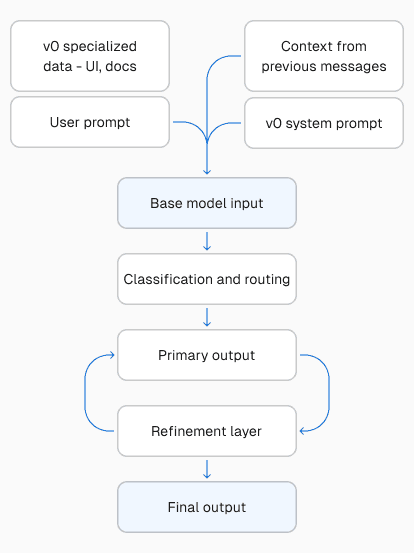
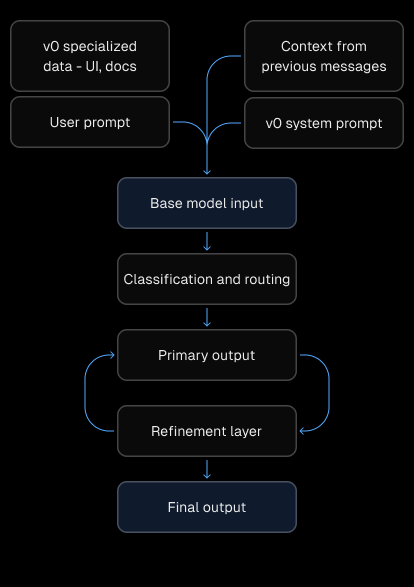
Link to headingHow does v0’s composite model work?
Pre-processing
When you send a message to v0, we take a number of steps to prepare input before making a model call.
First, v0’s system prompt defines v0’s response format and includes information about v0’s capabilities. We also include recent messages from your chat to maintain continuity, and summaries of older ones to optimize the context window.
Finally, we retrieve additional context based on your query from our own dataset, pulling from documentation, UI examples, your uploaded project sources, internal Vercel knowledge, and other sources to improve v0's output.
State of the art base models
For new generations or large-scale changes, our base model handles the generation task. This is a high-capability model chosen from the current set of frontier models, depending on which v0 model you're using.
For smaller edits, parts of your request are routed to our Quick Edit model that is optimized for speed. Quick Edit is optimal for tasks with narrow scope, like updating text, fixing syntax errors, or reordering components.
Because of v0’s composite architecture, base models can be updated or replaced as new models become available without needing to rebuild the entire model pipeline. For example, v0-1.0-md currently uses Anthropic's Sonnet 3.7 while v0-1.5-md uses Sonnet 4. The composite model architecture allowed us to upgrade the base model while keeping the rest of the stack stable.
Custom AutoFix model
While the base model streams output, v0 is constantly checking the output stream for errors, inconsistencies, and best practice violations. Our custom AutoFix model handles many of these issues mid-stream to further improve output quality.
Once the model finishes streaming, we run a final pass to catch any remaining issues that couldn’t be detected mid-stream. We also run a linter on your final output to catch and fix style inconsistencies and simple errors.
Link to headingHow do v0 models perform?
One of our primary evaluations for v0 models measures how often their generations result in errors. We’ve designed evaluation sets from common web development tasks and measure the rate at which models can produce error-free code while performing them. From our benchmarks, v0 models substantially outperform their base model counterparts.
v0-1.5-lg is a bigger model than v0-1.5-md but can make more mistakes, a common tradeoff in scaling AI models.
While error rates are similar across v0-1.5-md and v0-1.5-lg, we’ve found that v0-1.5-lg is better at reasoning about hyper-specialized fields like physics engines in three.js and multi-step tasks like database migrations. v0-1.5-lg also supports a much larger context window.
Link to headingTraining our own AutoFix model
Language models are stochastic, and each one comes with its own quirks. Some consistently over-format with markdown, others misplace files or introduce subtle bugs. We use a comprehensive set of evals, along with feedback from v0.dev users, to track these patterns and identify areas where output consistently needs correction.
These issues led us to build a pipeline that combines deterministic rules with AI-based corrections to catch and fix common errors during generation. Early versions of this pipeline relied on Gemini Flash 2.0.
To improve both speed and reliability, we trained our own custom AutoFix model, vercel-autofixer-01, in conjunction with Fireworks AI using reinforcement fine-tuning (RFT). Over the course of multiple training iterations, we optimized the AutoFix model to minimize error rates across a variety of tracked categories.
Performance optimization over training iterations
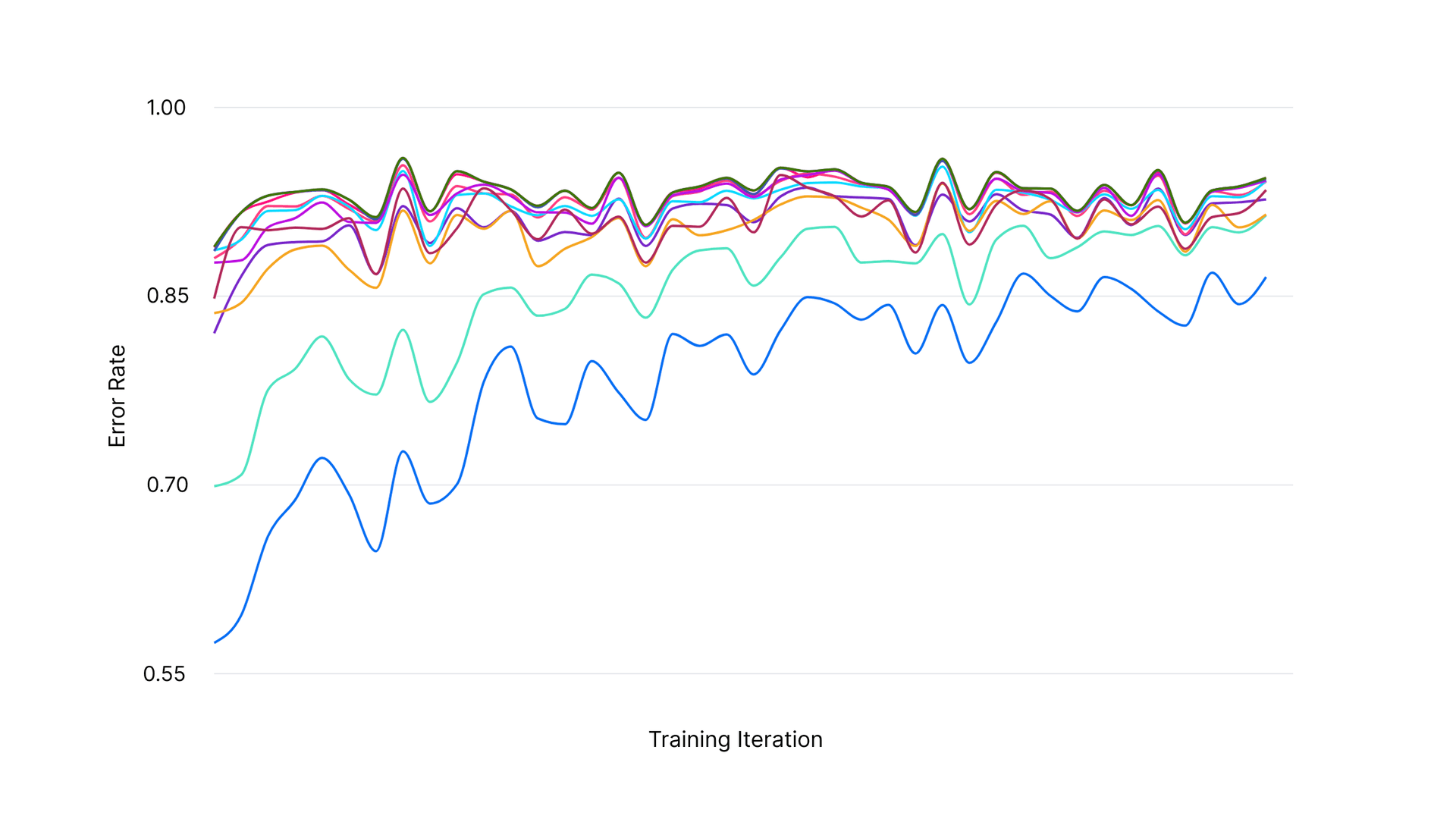
vercel-autofixer-01 was designed to quickly apply fixes while reducing error rates. On our error incidence evals, it performs at par with gpt-4o-mini and gemini-2.5-flash, while running 10 to 40 times faster.
Link to headingWhat’s next?
The v0 model family is available via API and in v0.dev. You can use v0 models in your favorite editors, or build custom workflows. For instance, you can leverage v0 to write scripts tailored to automated code migration. We’ll continue to improve our model output and release new model classes in the upcoming months.
¹: A notable exception is Perplexity Sonar, an "online" model.